A few years ago (was it really “a few” or just 1 or 2? It does not count as “a few”, right?), when I first saw how AI tools were able to generate code, to produce very reasonable answers, and to manifest other signs of “intelligence”, my first reaction was “oh, crap, the end is near”.
Fast forward, Microsoft has been pushing Copilots everywhere, NVIDIA is the most expensive company in the world, there are rumors of OpenAI Orion which would presumably outperform ChatGPT by 100 times, and you start feeling as if you are falling behind, a lot, especially when you are not into all of this yet.
But the interesting thing is that the whole AI field is clear as mud, so, try all you wish, but, unless you put some effort into making sense of it, you’d still be looking at the top of the iceberg. Well, unless you are one of the folks who have been working in that field for a while. Otherwise, the image below represents this situation quite well in terms of the actual complexity and the sentiment towards it (thank you “Microsoft AI Image Generator”, you did well):

As a side note, it’s almost unfortunate I’ve been working with the business applications for as long as I did, since that normally does not require ANY mathematical knowledge at all. Which would be very handy now once I started digging into the AI stuff. However, the amount of math needed depends on how far one wants to dig, so, after some initial suffering, I started to realize that it may not be that bad after all.
Either way, let’s get into it, and let’s just start with this: there is no intelligence there to begin with. All those models are just functions. Yes, you need a lot of computational power to calculate output, but it does not matter in general.
It matters, of course, for NVIDIA, since they are not only producing GPU-s to support those calculations, but they have also come up with CUDA, which is “a programming model and parallel computing platform that uses the power of a GPU to increase computing performance”, and which is proprietary to NVIDIA.
AMD got ROCM (their own api for gpu acceleration), so it’s not as if other GPU vendors were quietly dying off, but I guess NVIDIA was there first.
Either way, back to the LLM models… You need a lot of computational power to train them, you need quite a bit of power to perform LLM inference (so, to “use” them), but, ultimately, LLM-s don’t think. They just produce tokens and assign scores to those tokens based on the patterns observed in the training data. Given the same input, an LLM is supposedly going to produce the same output (it seems there can still be minor variations because of all sorts of concurrency and other errors that may happen along the way, but, in the perfect world, those outputs will always be the same for the same inputs). However, LLM’s output may include multiple tokens (words/word parts) with different scores assigned to each, and this is where it becomes probabilistic, since, depending on which token is, eventually, selected, you’ll see different results in the chat window. This is where SoftMax function comes in, then “temperature” parameter, etc. Have a look here if you need more details: https://www.vellum.ai/llm-parameters/temperature
Note: what’s the reason for all those hallucinations? There are multiple reasons, really, but this non-deterministic nature of the final output is one of those. Given a higher temperature, the AI tool may just present you with a combination of “tokens” which, once they put together, are simply misleading. But, even with the lower temperature it’s still possible – for example, if the training data for that model were inaccurate to begin with, it could produce inaccurate responses just because of that.
Now, let’s talk about Copilots for a moment, and let’s ask Copilot if it’s an LLM model:

Let’s ask ChatGPT, too:

The way I see it, Copilot’s answer is more accurate. For example, let’s ask ChatGPT “who is Donald Trump”. There is going to be a long answer, but here is the part that matters for the next experiment:

In other words, ChatGPT does not know about November 2024 elections.
However, let’s add a short file to the chat to let ChatGPT know about the latest events, and, lo and behold, there is a different answer now:
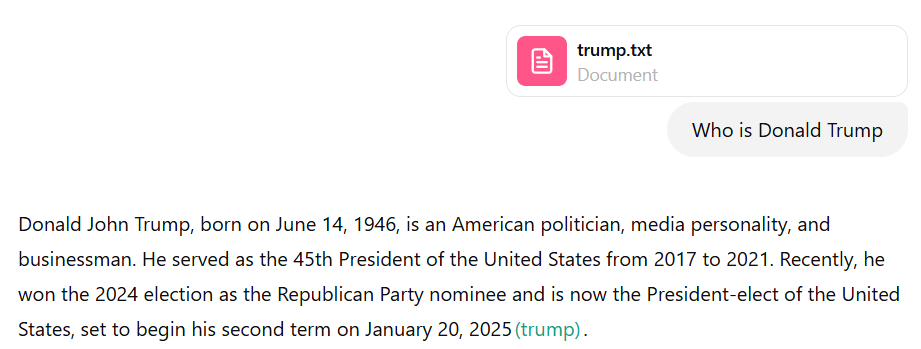
Why? Because now we are talking RAG, which is Retrieval-Augmented Generation. Basically, the AI tool (ChatGPT) would search the file I just added to the chat, it would essentially add search output to the “context” when passing my question to the model, and the model would adjust the response accordingly. It’s still the same model, it has not been magically retrained in just a few seconds… but, by employing RAG techniques, we got another response.
Point being, ChatGPT is not just the model, it’s, also, the whole set of techniques, algorithms, and software layers to augment model responses along the way. I guess “safety” layer would be another example of where LLM model is not the same as AI tool (since you would not be able to discuss certain topics with ChatGPT no matter how hard you try, even though, from the model perspective, it would not and should not care).
So, as an intermediate milestone, here is what we’ve looked at so far:
- LLM models don’t think. They are functions which are meant to produce the same outputs (tokens) for the same inputs
- Randomization is added on top of the model output to make final results more or less predictable / “creative”
- ChatGPT, Copilot, other AI tools… they are not “just” models. There are services/solutions which are relying on the LLM-s, but which are adding additional layers of functionality, and every vendor will do it differently
Ok, here is a question, though. Do you need ChatGPT or Copilot to utilize an LLM model? Well it depends.
There are various open source projects out there that you can install on your own computer to perform LLM inference. For example, you can use llamacpp: https://github.com/ggerganov/llama.cpp
It works fine, it takes an effort to install unless you’ve been doing it for a while, but, once installed, you can use different models with it. For example, I was able to use Mistral-7B on my 3 years old gaming laptop with RTX-2060 6GB GPU, and it was not that much slower than Chat GPT.
Of course the difference is that ChatGPT has 1.8 trillion parameters, and Mistral has 7 billion parameters. That’s huge, but, at least, I can run Mistral locally and I can get decent results:
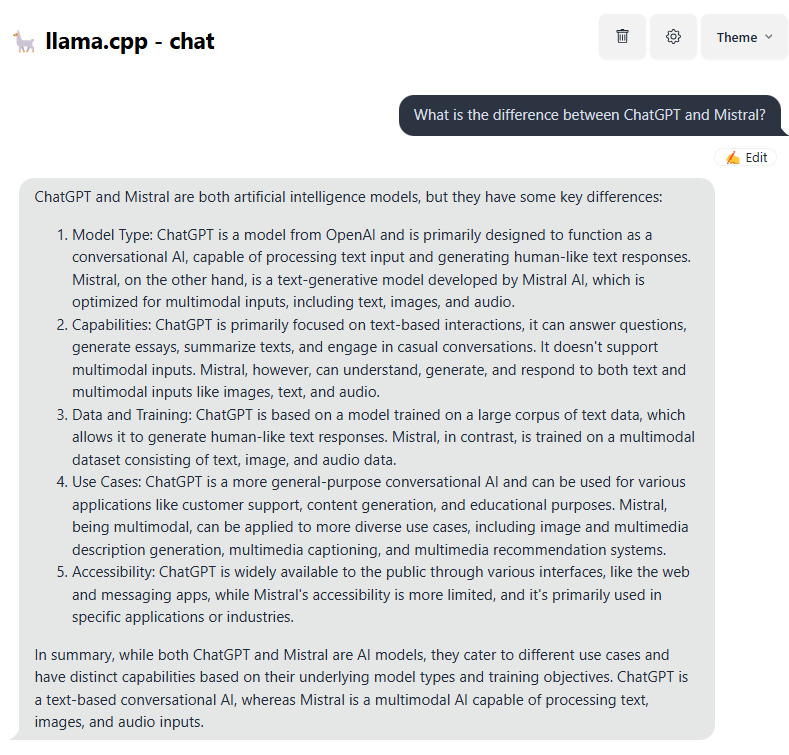
ChatGPT, when asked the same question, will structure the answer differently, but, ultimately, you can’t write off Mistral based on the fact that it has “just” 7B parameters. The answer I got above is very detailed, too.
However, if I wanted to use RAG with my local llamacpp server, would I be able to? Technically, I could do certain thing programmatically (there is an example here), but, as far as I’m aware, there is no “tool” I’d be able to install on my laptop which would add RAG to the mix.
And this is what we are paying for. We can deploy smaller models locally, there are various models out there, we can add more GPU power and deploy larger models, we can rent GPU-s and deploy even larger models that way for our own use. We don’t have to use ChatGPT, Copilot, etc.
However, those “commercial” AI tools come with the extra perks such as RAG and Safety, for example, which might be worth paying for.
However, will they be able to take our jobs? That’s a good one, and it depends. First of all, what are we talking about? Are we going to ask ChatGPT to create an enterprise-grade software application with complex functionality? That’s just not going to work. Not now, and, probably, not in the foreseeable future.
Why?
It’s a number of things: context length, hallucinations, incorrect requirements, non-deterministic nature of the SoftMax function. We have not talked about the context length above, but context window is, typically, limited. Which means the model will only have access to that much of the contextual information when trying to come up with the response. And, in order to write a consistent enterprise app, your context window must be huge (which is where developers often have issues, too. Someone implementing a given application module might not be aware of the other modules at all, and, as a result, the whole application may start looking as a patchy work). Now “context length” is not just about how much information you want to pass to the model, it’s, also, about how the model was trained. And, besides, the more information you ask it to use, the more computational resource you may need to dedicate to the whole process.
With all that said, how is human intelligence different from LLM-s? First of all, I don’t know. It’s a philosophical question to some extent; however, it’s worth mentioning that humans can do things without “words”. I bet you don’t need to tell yourself how to type text on your laptop, you can just do it. Even if that may require a bit a bit of exercising/training initially. Humans can rely on the rules where 2+2 is always 4 no matter what half of the internet might be saying (and, so, where an LLM model might easily start hallucinating), humans can run experiments to validate their statements, etc. Of course I can’t help but think that, perhaps, all of this will be achieved, eventually, by the AI models (just not necessarily by the LLM models), and that even brings up questions about whether we are… well… models in some way… but, ultimately, at this point it seems LLM-s can serve as co-pilots, but they need human pilots to realize their potential.